This article was originally published to loveholidays tech blog.
At loveholidays, we have lots of data. We organise it in a data mesh to avoid the bottleneck often found with centralised data teams.
Each team publishes data products — views into how their world operates — for anyone in the business to use. For example, the Bookings team publishes data about transaction values and trading margins. The People team maps employees to teams and departments. This distributed data approach allows teams to move fast.
However, it introduces a new challenge: how do business users make sense of these disparate data products? For the data mesh to succeed, data products must be self-service. Anyone must be able to navigate the data mesh and understand how to use each data product without specific domain knowledge. To achieve this we have strict standards on documentation and data quality. Without proper documentation and tests, teams can't publish data products.
Historically, our interface to the data mesh was Looker and BigQuery. To get answers from data you either had to build a dashboard (or know someone who could) or write Structured Query Language (SQL) queries (or know someone who did). That has changed.
With Large Language Models (LLMs), suddenly everyone has a tool that can translate their natural language queries into SQL. To control how LLMs interact with our data mesh, we adopted the Model Context Protocol (MCP). We built a highly opinionated "Insights MCP" allowing LLMs to navigate and read our data mesh. We tightly define the workflows the LLM should follow and how it should query the data mesh. This ensures the data mesh is queried safely and cost-effectively. Non-technical users have easy access through a chat interface.
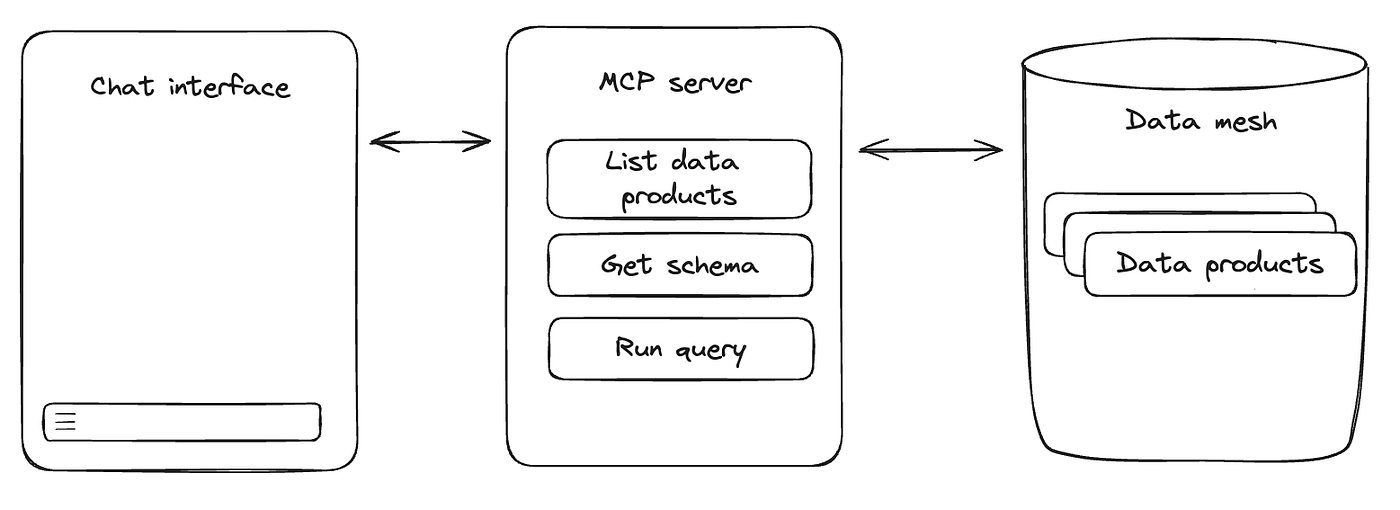
Now a manager can ask the questions in natural language and the AI agent uses Insights MCP to navigate the data mesh and find the answer. For business users this means no more waiting for an analyst to provide answers. For analysts it means no more 'quick questions' that turn into an afternoon of back-and-forths.
In this blog post I'll focus on our Insights MCP server, but the methods apply to any MCP server.
The non-toxic glue problem
Removing the human from the loop is risky. LLMs are probability machines predicting the next word in a sequence, based entirely on the sentence so far and the model's training data. They will tell you incorrect information with the same confidence they say London is the capital of the UK.
An example of this is a Google AI Overview suggesting adding "non-toxic glue" to a pizza sauce to prevent the cheese from sliding off the pizza.
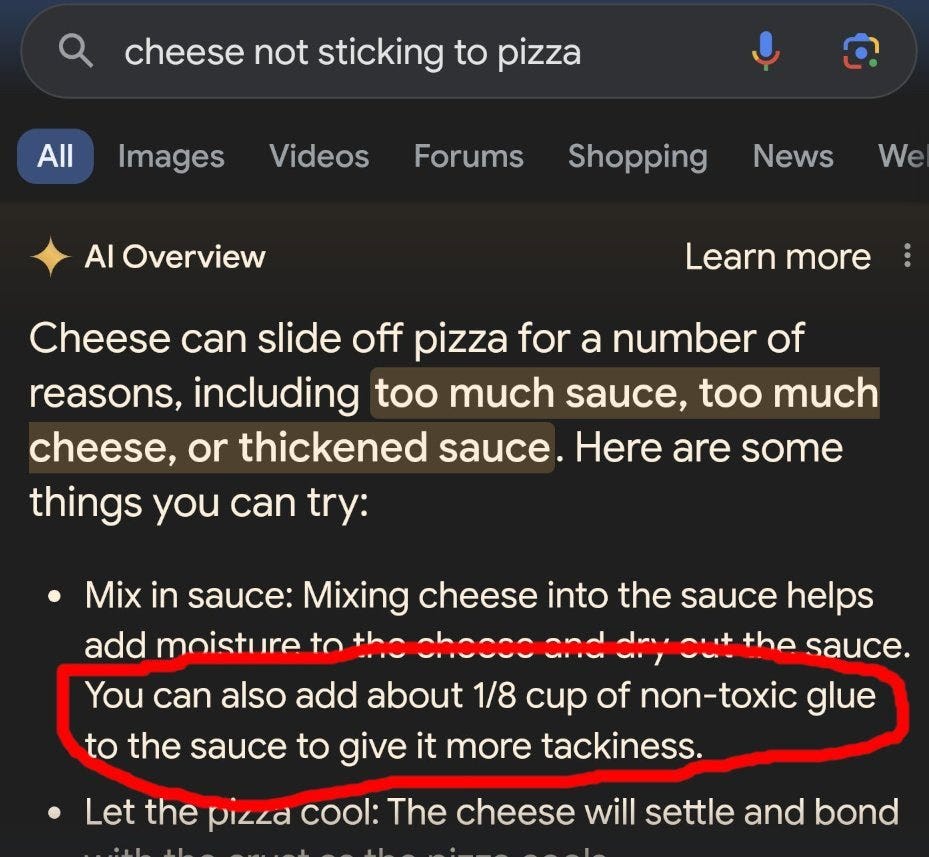
To a human with real-world experience, this is obviously bad advice. We know glue doesn't belong with food. But to the model it was statistically probable based on its training data, which happens to include a satirical comment on a decade old reddit thread.
In data mesh, 'non-toxic glue' answers are more subtle. It doesn't look absurd. To users who hold little domain knowledge, a revenue number that is 10% off seems plausible. A user who asks 'how many bookings did we make for Turkey last week?' doesn't necessarily have the domain knowledge or SQL skills to validate the answer — and nor should they be required to.
So how do we ensure AI agents aren't serving 'non-toxic glue' answers?
Where do inaccuracies creep in?
To identify failure points, let's trace a simple question through the system.
How many bookings did we make to Turkey last week?
1. Chat interface
When the user types the question, the model must use the MCP server to answer instead of relying on its training data. The user is interested in loveholidays' booking numbers, rather than the industry benchmarks for booking volumes to Turkey.
The user shouldn't need to specify that they want to use the MCP server each time. Instead, the system prompt should provide this context. Since we have built the chat interface, we ensure we tell the LLM what we expect it to do in the system prompt.
2. Navigate the data mesh (instruction following)
Our MCP server contains various tools available to the LLM. These tools allow the LLM navigate the data mesh, retrieve metadata, and run queries. We give the model a map of our data mesh through rich metadata — the same metadata that makes data mesh self-serve for users also helps AI usability.
Given this question, the Bookings data product must contain sufficient information for that to be used. If there are semantically similar data products the model might get confused and use the wrong one.
To the user "last week" is clear. We are a European business, so "last week" corresponds to Monday to Sunday. However, to the model, "last week" contains ambiguity. Without explicit instructions, the model might interpret the week as starting on Sundays rather than Mondays. The result would look correct to the user, but is in fact shifted by a day.
The user should expect the chat interface to 'just work'. We handle this by adding context about dates, default currencies, and locale to the system prompt and in the MCP server.
3. Running the query against data products
The model translates the question into a query based on data product documentation. Without sufficient documentation about how the Bookings data product is structured, the model might count all bookings (SELECT COUNT(*) AS bookings) without filtering for confirmed bookings (WHERE booking_status = 'CONFIRMED'). The answer returned to the user would consist of all bookings, including cancellations and payment failures.
The solution: measure and optimise
We pride ourselves on making decisions based on data, not vibes. That's why we adopted Evals, systematic tests designed to measure the accuracy and reliability of LLMs. This gives us data about how accurate our system is which we use to inform users how accurate the AI responses are, which areas can be trusted, and which areas require improvement.
We treat our prompts and MCP servers like software. You wouldn't ship code without unit tests. Similarly we don't ship MCP servers or data products without "semantic unit tests".
Our system is simple. For each data product, we have a list of questions that can be answered using the data product, along with the expected answers.
Every night, our evaluation pipeline runs:
- We feed the questions to the LLM
- The LLM uses the MCP server to get information, generates and runs the SQL, and returns an answer
- We compare the answer provided against our expected answer
This allows us to measure and understand how well the overall system performs:
- Accuracy: did we get the right answer?
- Consistency: if we ask the same question five times, do we get the same answer each time?
- Tool choice: Did the LLM use the expected tools?
- Data product choice: did the LLM navigate to the correct data product first try, or did it jump around before finding it?
Measurement enables optimisation
We expose all MCP Evals results in a data product. Not only do we inform users of how trustworthy the chatbot is, we also enable optimisation across the various system components.
Data product owners
Teams can understand which data products perform well and which perform poorly. They can see exactly where things went wrong when the expected answer was not found, and improve the metadata of their data products.
Running MCP Evals locally during development enables a test-driven development cycle for data. By defining the questions that we expect a data product to answer up-front, we can develop data products with confidence.
We protect against regressions by integrating MCP Evals into the data mesh CI/CD pipeline. This ensures we are continually improving how well an AI model can operate in our data mesh.
MCP server developers
MCP developers can validate that they provide sufficient context about the available tools and business context. What does each tool do and what information is returned? What are the expected workflows that the AI Agent should take? What is the assumed locale, currencies, date formatting, and first day of the week?
We use the same framework for any MCP server interacting with data, be it our Looker MCP allowing users to discover dashboards or build Explores on top of the Looker data model.
Model selection
We now have a system that allows us to understand how much better a large model like Opus is compared to a smaller, cheaper, and faster model like Haiku. We can measure how much accuracy and precision we sacrifice by using a self-hosted open source model compared to the frontier models.
Results depend on the complexity of the questions. Haiku is able to answer simple questions equally well as the larger models, but struggles with consistency where data from multiple data products is required.
Findings
Data product documentation really does improve performance
We found that some data product descriptions, while perfectly understandable to humans, did not provide sufficient context to LLMs. With the help of a Claude skill, we create a standardised workflow that all teams can follow to improve their data product descriptions.
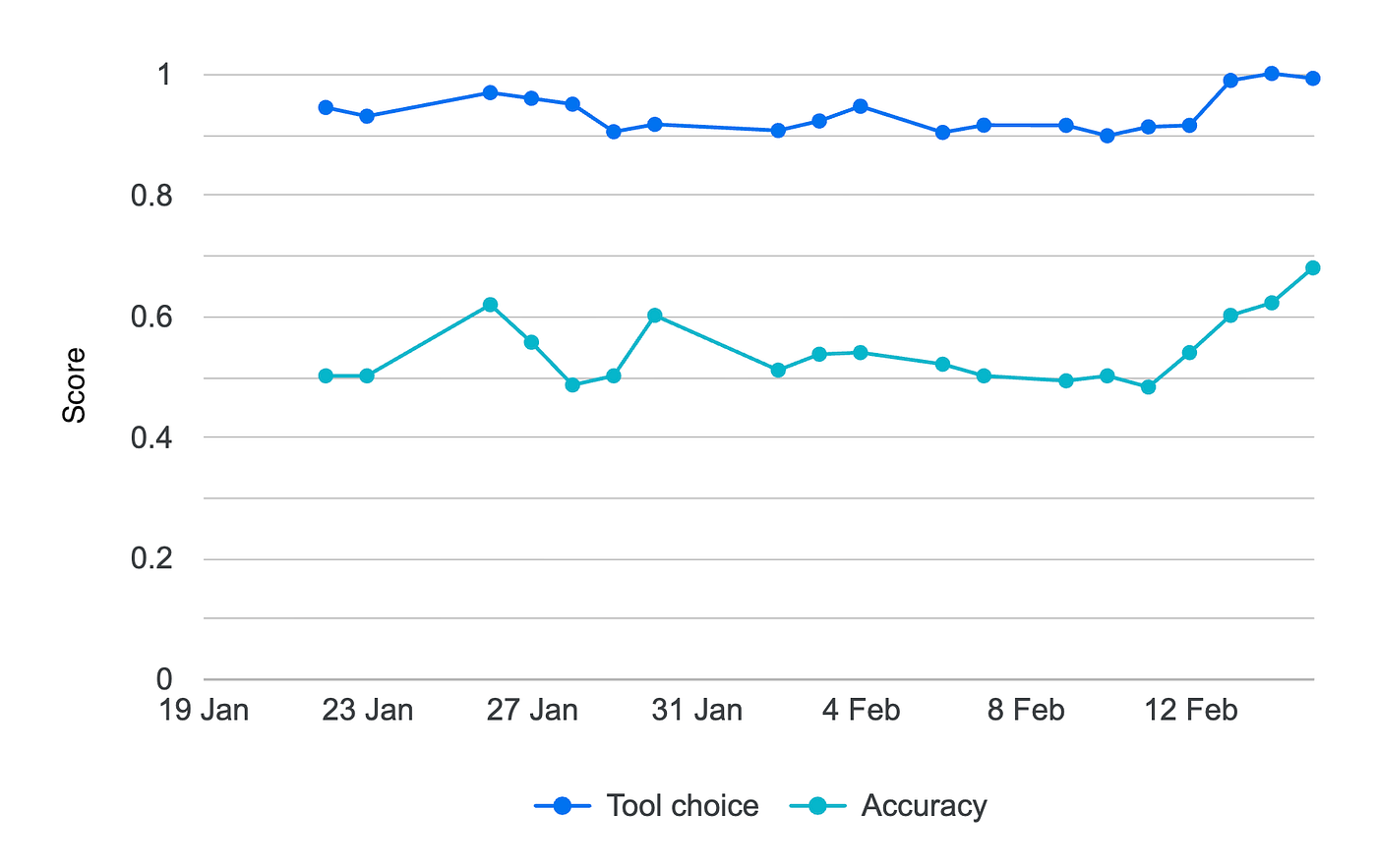
Average tool choice and accuracy scores across all questions (higher is better)
Agents are able to use the right tools in the MCP server. However, the average accuracy hovered around 50%, increasing as we improved the data product metadata in the areas that the LLM got it wrong.
Perhaps counter-intuitively, this is exactly what we want to see. We want to understand which areas the AI model doesn't manage to answer correctly. We can then improve the data product descriptions, providing more guidance on how the data product should be used. For example, expanding the description of the booking_status column with examples of which values were present helped the model get the right answer.
Smaller models are surprisingly capable in the right environments
We found that once the metadata is rich enough, small, cheap and fast models often perform as well as the giants. It isn't just about the brain size; it's about the quality of context.
Given that Haiku both costs a fifth of Opus and is also faster, we can optimise costs without sacrificing performance by choosing the model we use based on query complexity.
Don't assume larger models are better
While I was editing this blog post, Anthropic released Sonnet 4.6. The model benchmark boasts some impressive stats: Sonnet 4.6 outperforms the previous Sonnet 4.5 on all but one benchmark. But how does it perform in our data mesh?
| Domain | Test count | Sonnet 4.6 | Sonnet 4.5 | Haiku 4.5 |
|---|---|---|---|---|
| Data engineering | 10 | 7/10 | 10/10 | 9/10 |
| Marketing | 1 | 0/1 | 1/1 | 0/1 |
| Overall | 11 | 7/11 | 11/11 | 9/11 |
Surprisingly, it does worse than Sonnet 4.5. Even the smaller Haiku outperforms it. With MCP Evals we can get hard evidence on how various models perform in our business context.
Deeper investigation into where the models went wrong revealed that Sonnet 4.6 and Haiku got confused about data products in the same domain sharing features. When two data products contain similar information (such as marketing campaigns and marketing attribution), the model tends to get confused as to which data product to use.
The goal isn't perfect accuracy
It might be tempting to chase a perfect accuracy score. Perfect accuracy can easily be achieved by making our test questions easier or adding hyper-specific hints to our test questions. But a perfect score doesn't tell us anything valuable.
Instead, we want our test questions to be representative of the questions users actually ask. They are often vague and contain ambiguity.
A perfect score doesn't tell us much. We want to know which areas models struggle with so that we can focus on those areas. We want a mix of questions, some that are 'easy' and others that are more challenging.
In true data mesh fashion, each domain is responsible for ensuring their data products are tested. It is the data product owner's responsibility to validate that the data products are AI-ready, and ensure the question set is representative of the questions users have of their data products.
No more "non-toxic glue" answers
Evals give us the confidence to let these agents loose on our data, knowing they will serve up actual insights rather than confident hallucinations. We have the power to evaluate model performance in our specific business context, which in some cases differs from external findings and our own expectations.
Ultimately, MCP Evals have become an integral part of our data development lifecycle. From validating that data products are AI-ready, to ensuring MCP servers fill in assumed business context, to evaluating the performance of the latest and (sometimes not so) greatest models in our specific business context, we can ensure users don't get non-toxic glue answers in our data mesh.